Though it’s still April, I’ve already begun to hear people ask the question that is on many minds – will Dreamforce happen this year?
Personally, it’s hard to see how it can, at least in it’s usual form – it’s hard to imagine that in November it will make sense to bring in 170,000 people from all over the world and place them in close proximity (and you know how close people crowd together during Dreamforce). Given the values of Salesforce and our Ohana to not put people’s lives at risk, and the science driven decision making by our state and local governments that is perhaps less susceptible to emotional, irrational and political pressure than seems to be the case with other states, it would take a medical miracle. Such a miracle could happen – we are talking six months from now. But even as we hope for such a miracle, creating some backup plans would seem prudent.
So what might such backup plans look like? I’m sure the folks at Salesforce are asking themselves “how do we translate the Dreamforce experience into a virtual experience?” Along the way, I am sure they will look at best practices from other conferences that have gone virtual.
But I think this is also an opportunity. There is a real need to reinvent virtual conferences beyond a series of video-conferencing calls and webinars. And I think Salesforce is the right company to pioneer this. I’m going to share some thoughts – I doubt they could be implemented by November, but perhaps early steps can be taken.
The challenge with virtual conferences is that we’re all tired of sitting in front of screens and watching things. Besides, a conference isn’t just about watching sessions – it’s about exploring, and connecting with peers, customers and vendors. It’s about engaging – a conference is not a passive activity.
If only there were a way to make a virtual experience that is as engaging – or even more engaging – than a physical conference….
Oh wait – there is one… A virtual experience so engaging that tens, maybe hundreds of millions of people experience it every day. One so compelling that it’s often hard to leave. And one that generates billions of dollars of revenue ever year.
Yesterday I was honored to be once again awarded the tile of Salesforce MVP.
Today, the COVID-19 virus was declared to be a pandemic. I don’t think there’s a connection…
That said, I wanted to take a step back and say a few words about what it means to me today and going forward. As an MVP I have a responsibility – to share what I know, to contribute to the community, and to strengthen our Ohana. Usually for me this means sharing what I discover about technology, through writing and through presenting.
But today there are priorities – we, our entire Ohana – is facing a crisis. Salesforce has already taken a lead in this, being among the first companies to shift to remote work as much as possible, taking conferences virtual, and supporting its hourly workers. The importance and impact of this cannot be overstated – those actions will save lives.
As a Salesforce MVP, and as a human being, I feel an obligation to follow and lead in a similar way. I recently and very reluctantly withdrew from speaking at London’s Calling. As someone located in a developing “hot spot”, I could not risk the possibility of bringing the virus there (nor was I excited about the prospect of being quarantined far from home). I wish them the best and know they will take the necessary precautions for those who attend – and I very much look forward to attending in the future – it’s a great conference.
I’ve recently posted articles on Linkedin (see the list here) that I’m hoping will be helpful to people in their thinking and coping with the developing situation.
I expect I will not be speaking much this year (though I did submit a proposal for virtualdreamin – an event that could not be more timely), but will instead find other ways to contribute.
I am so grateful to be a part of this community, and honored to be an MVP. But today, more than anything, this means doing what I can to encourage others to do everything possible to remain healthy and slow the spread of the virus. We can talk technology tomorrow.
As process builder has grown more capable, it has also grown in its ability to consume CPU time. Most of the time, this won’t matter – however, if you aren’t careful, your carefully built process that works just fine with individual records, will blow up spectacularly when you start doing bulk operations. Using the Evaluate Next Criteria option can be a major contributor.
The reason is simple – at this time, one of the greatest consumer of CPU time in processes is the criteria – the rule.
Let’s look at a simple example:
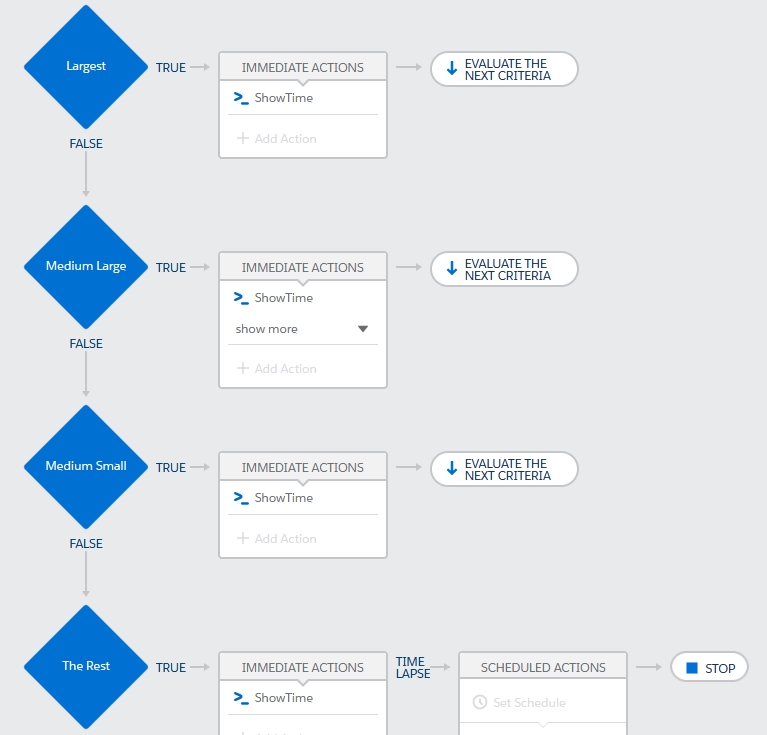
This process has four criteria nodes that divide up states by the size of the state. Each of the criteria has simple formula rule such as this one that identifies the largest states: CONTAINS(‘CA,TX,FL,NY,PA,IL,OH,GA,NC,MI,NJ’, [Lead].State ) . The action calls out to an Apex method that logs consumed CPU time (trust me when I say this action costs very little CPU time).
Now imagine inserting 200 leads distributed evenly across all 50 states. With the process as is, all of the leads are evaluated by each node, regardless of the fact that it is impossible for a lead to qualify under more than one criteria (a lead can’t be in two states at once). The average time consumed was 303ms.
Running the same lead insertion after modifying the process to stop after each criteria is met, results in fewer leads being evaluated on each criteria node. In this example, since we distributed the leads equally by state, 75% will be evaluated on the second node, 50% on the third, and the rest on the last. This reduces the average CPU time consumption to 250ms.
What if all of the records belong to California – in other words, all of them match the first criteria node? In the first process example, where “Evaluate the Next Criteria” is set, there is no difference in CPU time! It still consumes 303ms. This makes sense, as all of the leads are evaluated by each rule.
However, when using the second process that does not evaluate the next criteria, in this scenario only the first criteria is evaluated and the average CPU time drops to 185ms!
Minimizing Rule Execution is an Essential Part of Process Builder Optimization
Executing criteria nodes is costly – by my estimates it runs 75-100ms per criteria against 200 records. When considered in terms of overall CPU time usage, this means that if you execute 100 criteria across multiple processes and sub-processes, that alone may be enough to exceed CPU limits even if nothing else is present in your org (workflows, actions, Apex, validation rules, etc.) – and who has that? Hopefully this will be an area where future optimization work will be done, but for now, it’s essential to design your processes to minimize the number of rules that execute – and stopping evaluation as soon as possible is a great start.
Update: I was asked if this advice contradicts the “One Process to Rule Them All” design pattern of combining multiple processes on an object into one and using the “Evaluate Next Criteria Option” in that case. It does not. There are two reasons why: 1. Combining criteria into one process will cost the same or less CPU time than having it in separate processes. 2. Combining processes into one makes it possible to add an initial negative criteria node – one that stops execution for any record that does not meet any of the subsequent criteria – thus improving efficiency over having multiple processes where each criteria is evaluated for every record.
Methodology Benchmarking CPU time usage is tricky. I have an entire section in my book “Advanced Apex Programming” about how it’s done, and you can find how those techniques can be applied to declarative constructs in a talk Robert Watson and I did at Dreamforce back in 2016 called “It’s About (CPU) Time – The Dark Art of Benchmarking“. The specific numbers in that talk are long obsolete, but the methodology is sound, and I’ve continued to use it to examine Process Builder. The numbers here were generated on a API 47 scratch org on 2/4/2020. Preliminary testing shows comparable numbers on an API 48 Spring 2020 preview org). Numbers were averaged across 5 tests.
There. I said it. Blasphemy right? When it comes to Salesforce triggers, it’s common to think about frameworks. What’s the best framework to use? Should I find one or create my own? A framework can offer efficiency – code reuse and code you don’t have to write yourself. It can provide discipline – everybody has to use the framework. It can improve reliability and maintainability, and make problems easier to debug.
And in a brand new org with a single development team, you can make it work – 100% enthusiastic adoption.
But we live in the real world. And real orgs are often.. well, a mess. Or, to adopt a more Orwellian term- a “Happy Soup”. There are multiple development teams, some of whom don’t talk to each other. There’s no way they would all agree on a single framework. And the cost and risk of rewriting existing code into a framework is prohibitive. Nobody knows what half the code actually does anyway.
That’s right, in the real world, trigger frameworks are not nearly as useful as they sound. But that doesn’t mean you should give up. As it turns out, it’s possible to apply the same design patterns that trigger frameworks use when working in “Happy Soup” orgs. It’s possible to make small incremental changes that have massive benefit. In fact, you can achieve most of the benefits of a trigger framework at almost no cost and no risk.
I’m pleased to announce the immediate availability of the fourth edition of Advanced Apex Programming!
I know what you’re thinking – what has changed? Do I really need a new edition?
Well, the first thing you should know, is that this book is about 20% larger than the previous edition. But, the price is the same – instead of increasing the page count, I was able to increase the page size – from 6 x 9 to 7.5 x 9.25.
And what’s in that 20%?
Here’s a brief summary of the major changes for this edition:
Chapter 2: The section on “Controlling Program Flow” has been largely rewritten with a new example.
Chapter 3: The sections on “CPU Time Limits”, “Benchmarking”, “24-hour Limits” and “Other Platform Limits” are new or have been rewritten.
Chapter 5: There’s a new discussion on detecting duplicate fields in dynamic SOQL queries.
Chapter 6: The trigger framework has been enhanced, with particular attention to handling record DML updates across multiple trigger handlers (a subject discussed in previous editions but not actually demonstrated).
Chapter 7: New coverage of platform events.
Chapter 9 is a completely new topic: Application configuration. The previous chapters 9-12 are now chapter 10-13 and the following paragraphs refer to them by their new chapter number.
Chapter 10: Additional discussion of platform events.
Chapter 11: Revised recommendations for unit tests and managed packages.
Chapter 13: Updated for Salesforce DX
So even if you don’t buy this new edition, please don’t read the previous one – the platform has changed, and many of the earlier recommendations no longer reflect best practices.
And by the way – the Kindle edition is still priced considerably lower than the print edition – so that offers an inexpensive way to check out what’s new without buying a new printed book, for those of you who are more cost sensitive (I do recommend the printed book in general though, as listings just don’t come through that well in the eBook editions).
As always, watch for corrections and updates here on advancedapex.com – as I’m quite sure Salesforce will continue to update the platform faster than I can revise the book 🙂
Last week I had one of the hardest. It only happened occasionally, after a row lock error, in very specific scenarios, on a customer production org. It was, of course, impossible to reproduce. And given that it only occurred now and then for random users, capturing a debug log was out of the question.
So what do you do? You go old-school. Search the code for any execution path that could possibly lead to the results we saw in the data. And after many hours of research, I found nothing. There was no scenario that could lead to the results we were seeing. And there were no workflows, processes or flows that could do it either. We started wondering if maybe some outside integration was involved, but that seemed unlikely.
Well, there’s that old saying “When you’ve eliminated the impossible, whatever remains, however improbable, must be the truth”. There was one “impossible” code path that could theoretically lead to what I was seeing, but it could only happen in one case – if you could somehow read a field from an SObject that was not included in a query, having it return null instead of throwing an exception.
You’ve all seen this exception. Imagine a custom object Soql_Query_Test__c that has two fields, Test_Field_1__c and Test_Field_2__c and you execute the following code
Soql_Query_Test__c sqt =
[Select ID, Test_Field_1__c
from Soql_Query_Test__c Limit 1];
String s = sqt.Test_Field_2__c;
The result is the notorious SObjectException “SObject row was retrieved via SOQL without querying the requested field: Soql_Query_Test__c.Test_field_2__c”
I’ve seen that exception many times. It’s invaluable during development and testing when it comes to making sure that all of the fields we use are in a query. But the only way our bug was possible was if I could read an unqueried field without raising that exception.
I tried everything I could think of – converting the object into a generic SObject, passing it to functions and accessing the field there. The exception always appeared. Was I on the wrong track? Was this actually happening? What could our code be doing?
Fortunately, we have unit tests – good unit tests. We even have unit tests that simulate row locking exceptions, so I was able to run that code path, though not for the exact scenario that would reproduce the bug. Still, I could set some fields in a source record, add some debug statements and see exactly what happened.
And sure enough, the improbable was true. I had a record. It had a field that had a value in the database but was not included in the query. I confirmed it was not included in the query using the wonderful SOBject.GetPopulatedFieldsAsMap function. But when my code accessed the field, the value was null. No exception. Null. I was floored.
I started trying other things in the org where I was experimenting – different field types, dynamic vs. static DML, dynamic vs. static queries, and finally had a breakthrough. I set the other field to a random value, and the exception vanished.
Soql_Query_Test__c sqt =
[Select ID, Test_Field_1__c
from Soql_Query_Test__c Limit 1];
sqt.Test_Field_1__c = 'Changed value';
String s = sqt.Test_Field_2__c;
This results in no exception, and the string is set to null.
If you set any field in a record, reading any unqueried field on the record will return null instead of raising an exception.
I had my answer, and was able to implement a solution so we could patch the bug. But I’ll be honest, at this point my biggest question was – how could I not have known about this?
Is it a Bug, or a Feature?
The next day I reached out to Don Robins who is an expert trainer. He knew about this, and his view, and that of another trainer he spoke to was that this was a known and expected behavior. The reasoning: that once you set any field in a retrieved record, further missing field SObjectExceptions are disabled under the assumption that you (the developer) know what you are doing at this point.
This post suggests that it was a bug that was introduced late 2017. But I knew our code dated to mid 2016. Fortunately, it’s possible to set the API version for an Apex class, so I set the class I was experimenting with to API 24 – which is about 6 years ago – and saw the same behavior. This leads me to conclude that either this behavior has always existed, possibly by design, or that it was an unversioned change.
You may wonder how could an unversioned change this significant occur and not be detected? What about the infamous Hammer test?
Well, think about what would have actually happened when this change was introduced. Existing code would continue to work. The lack of an exception would only break a test that was checking to verify that a missing field exception occurs – and what would be the point of such a test? In truth – this is not going to be a breaking change, and while it might have been caught by an internal Salesforce validation test, it’s highly unlikely any customer orgs, functionality or unit tests would be impacted.
A friend of mine at Salesforce brought the following known issue to my attention: https://success.salesforce.com/issues_view?id=a1p30000000jfXtAAI suggesting that it is a bug. And yes, I did miss this when searching for existing issues before doing my own research. Oops – lesson learned (again).
So this brings us to the big question: is this a feature? Is it an unversioned change? Or is it a bug? And ultimately, should this behavior be changed?
It’s not an easy question to answer.
Does it make sense to ignore unqueried fields once you’ve set any field value? I can see the logic in that argument, but let’s rephrase it.
When updating a record, do you ever read fields on that record? Of course you do. And is there any scenario where, on reading an existing field, you would intentionally leave it out of the query string in order to return null instead of the existing value? Probably not.
Yes, you can make the argument that the developers should know what they’re doing and make sure to query all fields, but we developers make mistakes. And the earlier we find a mistake, the better. Which scenario is more likely to help discover a missing query term earlier – an exception, or returning null? Obviously, the exception. The only way you’d detect the incorrect null field value is if you looked for it, or saw the consequences later in the data – as I did. So while it makes sense to me to allow writing fields that were not queried, I think it would be better for developers to have the exception always occur when accessing unqueried fields that have not been explicitly set.
So I’m leaning towards the “it’s a bug” camp… but is this a bug worth fixing?
The nature of this “bug” is the lack of an exception. How much code exists out there where someone queries a record, writes a field, and then inadvertently reads an unqueried field? Especially considering that this behavior may have existed from the earliest days of Apex? I’m afraid to even ask – the number could be enormous.
Sure, they would version this fix. But then you’ll have a new version of Apex where an exception might be thrown that wasn’t thrown before. Everyone will have to test their code. Unit tests will help, but only for those who have good unit tests, and even then, there can easily exist code paths where the bug was missed – which could lead to the sudden appearance of intermittent and occasional exceptions in code that is currently working for anyone who wants to upgrade their code to a new API version. For some orgs this could present a costly and risky obstacle to upgrading to a new API version – at exactly the time where the new Apex compiler promises to bring new enhancements to the language.
So yes, it may be a bug, but this may be a bug where the cure costs more than it’s worth. In which case, there’s only one thing left to do – turn it into a feature and document it.
Whichever approach they choose, this has been a fascinating case – I hope you found it as interesting as I did. And please spread the word – this behavior is something every Apex developer should know about and consider both at design time and when creating unit tests and QA plans.