Dynamic Bulkification
I know what you’re thinking. What is “dynamic bulkification”? Is it some new terms that I’ve just made up to represent some wild new Apex design pattern?
Yep, that’s about right.
I discuss this in my April appearance in Salesforce Apex hours – you can watch the full video here:
Or, you can read about it in this article below.
Let’s Talk About Integrations
As an ISV partner, I see a lot of orgs. Many of them have integrations with outside services that use APIs to insert and update Salesforce records. Historically, integrations have used the SOAP API, though recently more of them are using the REST API.
The SOAP API is not an easy one to use. It uses XML as the data format and is programmatically rather complex. The REST API is much simpler and uses the common JSON format. So it makes sense that new integrations are using REST and older ones gradually migrating to it. However, the SOAP API does have one advantage over REST – all of the Salesforce SOAP API commands use arrays for transferring record information. In other words, bulk operations are just as easy as individual record operations. So integrations using SOAP would typically perform bulk operations.
You can perform bulk operations with the REST API – they are called composite operations, but they are more complex than the default single record operations. The documentation covers them almost as an afterthought. As a result, anyone learning how to use the Salesforce REST API will inevitably learn the single object patterns first, and may never even notice the composite patterns. Indeed, if you don’t read the documentation carefully, you might conclude that the single object patterns represent best practices.
As a result, we’re seeing more and more orgs that are experiencing a very high frequency of single record operations from integrations. This is not a good thing.
High Frequency Record Operations
Consider a relatively simple org – one with few triggers and little automation, that is experiencing a high frequency of single record operations. Each incoming API call results in an operation in Salesforce, but as long as the Salesforce processing time is short, you’re unlikely to see any problems.

It’s also unlikely that the company building the integration will see any problems, because this is very likely to be the scenario they test for.
But what happens when you start adding additional functionality to the record processing in the form of Apex triggers and automation? The processing time for each request will inevitably increase resulting in the following scenario:
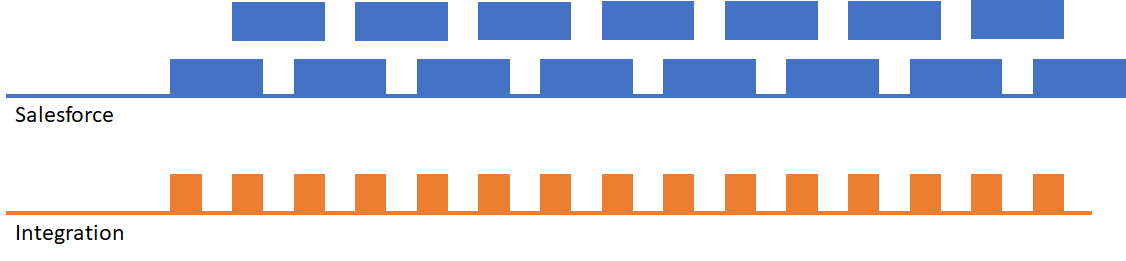
As you can see, Salesforce will still be processing one request when another comes in. However, this may not be a problem, as the different triggers will run in different threads – in parallel. So everything is fine unless…
High Frequency Record Operations with Locking
What happens if the API request and corresponding Apex and automation causes a record lock? This can happen when trying to insert or update records that reference a common object. For example: if you tried to update multiple contacts on the same account. The one we see most often is that of a marketing or sales automation system that is trying to insert multiple CampaignMember records on the same campaign – each individual insertion creates a lock on that campaign.
This results in the following scenario (where a red block indicates a locking error):
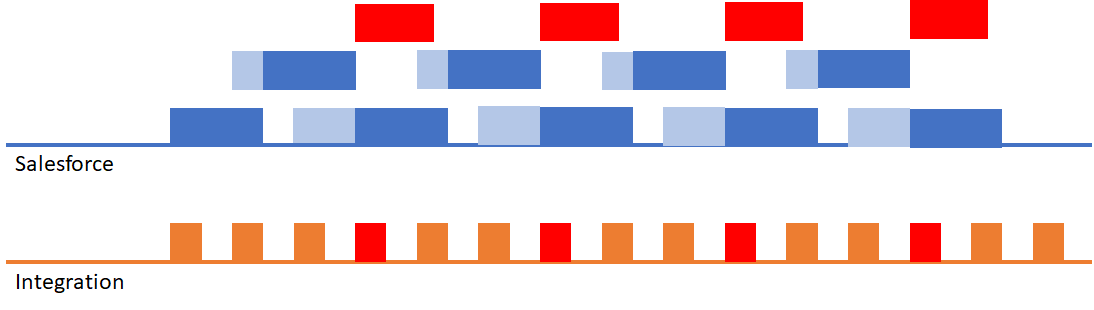
In this scenario you’ll starting seeing API failures on the integration due to record lock errors.
How can you address this scenario?
You could ask the integration vendor to stop performing individual record operations and bulkify their integration. That’s the right solution, but good luck convincing them to do so. No, in the real world it’s up to you to resolve this.
The obvious first solution would be to reduce the processing time for those individual record operations. You’re probably already familiar with the best ways to do this:
- Dump Process Builder (Use flows or Apex – process builder is horrifically inefficient)
- Prevent reentrancy (triggers that invoke automation that invoke triggers and so on)
Another common approach is to move part of the processing into an asynchronous context, typically a Queueable operation.
High Frequency Record Operations with Asynchronous Processing
Moving part of your processing into an asynchronous context results in the following scenario:
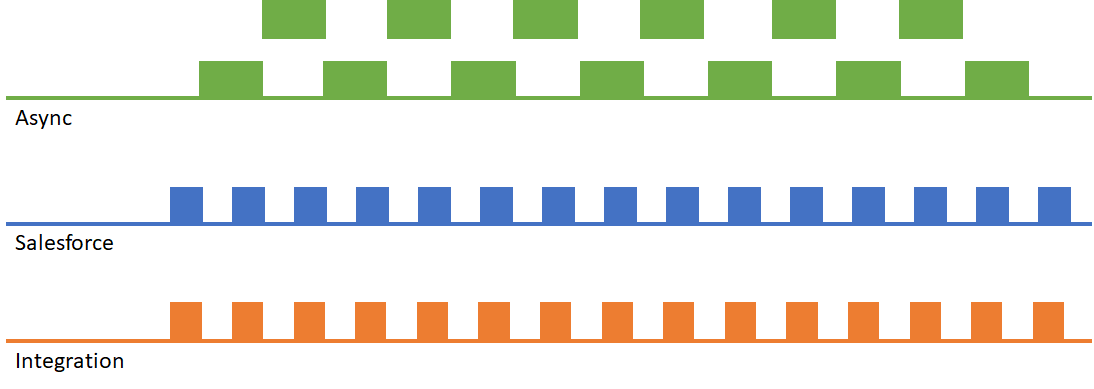
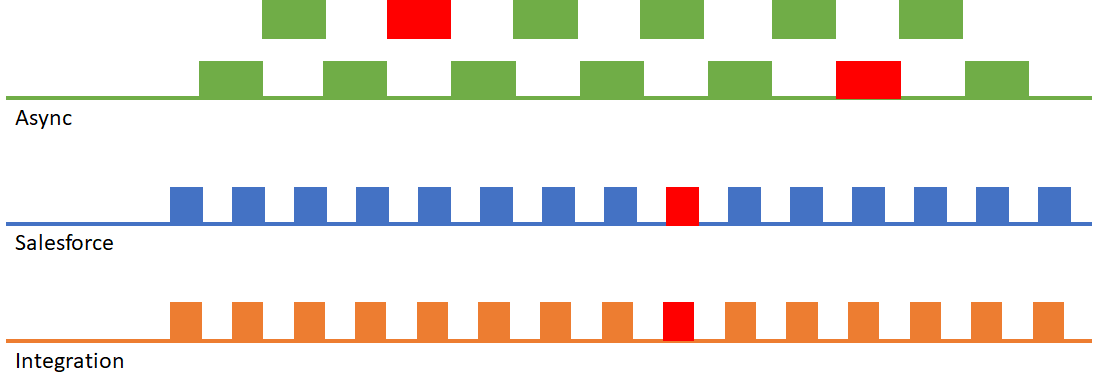
This approach also results in a very high number of asynchronous operations, which can be a problem on larger orgs that are already nearing their 24-hour asynchronous operation limit.
Dynamic Bulkification to the Rescue!
Which brings us to the design pattern that led me to introduce the term “dynamic bulkification”. The idea here is simple – translate large numbers of individual record operations into a single bulk operation as shown here:
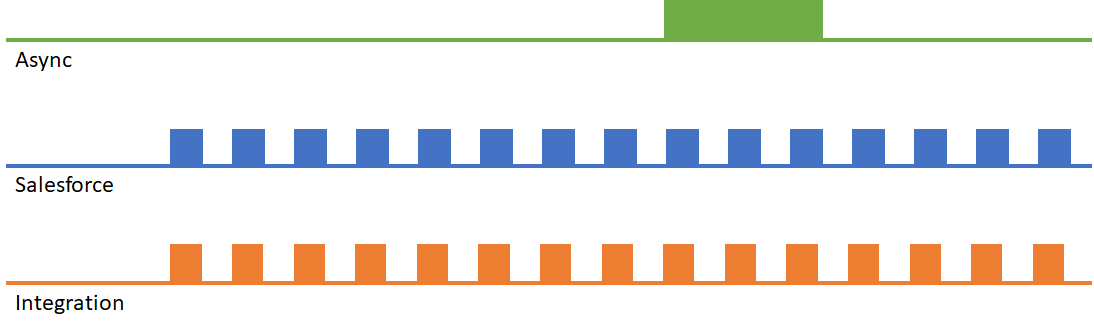
This approach is a fantastic solution to the problem. That’s because Salesforce is optimized for bulk operations – in most cases the time to perform a bulk operation is far less than the sum of the times of the individual operations. This also results in considerably fewer asynchronous requests, depending on how many single requests can be combined into one.
The question then becomes – how does one implement this?
One approach is to use platform events.
Platform events are self-bulkifying. That is to say, while you may publish individual events, your platform event triggers will always receive groups of events.
While this may seem the ideal solution, there are some problems with this approach:
- Platform events are not 100% reliable. Event publishing can fail, and even events that are successfully queued may fail to publish or be delivered.
- If your asynchronous operation is inefficient (unbulkified, or performs DML operations that invoke process builder), you won’t gain the full benefits of the bulkification.
- Platform events currently run with synchronous context limits (which are lower than the asynchronous context limits).
- Platform events are not ISV friendly – there are challenges with incorporating them into packages (platform event limits and quotas are common to the org and packages).
I won’t say that you shouldn’t use platform events for dynamic bulkification. They are probably good enough for most scenarios. But if reliability is a priority, or you are building for an ISV package, they are probably not the right approach at this time.
Dynamic Bulkification with an Asynchronous Framework
A more reliable approach is to build on an asynchronous processing framework. Such a framework uses a custom object – call it an async request object – to represent async requests to be processed. I won’t go into detail on how these frameworks operate, or all of the advantages of taking this approach. You can read all about it in chapter 7 of my book “Advanced Apex Programming”, where I discuss this approach in depth.
What I don’t discuss in the book is the possibility of merging async request records of the same type in order to perform dynamic bulkification. This results in the scenario shown here:
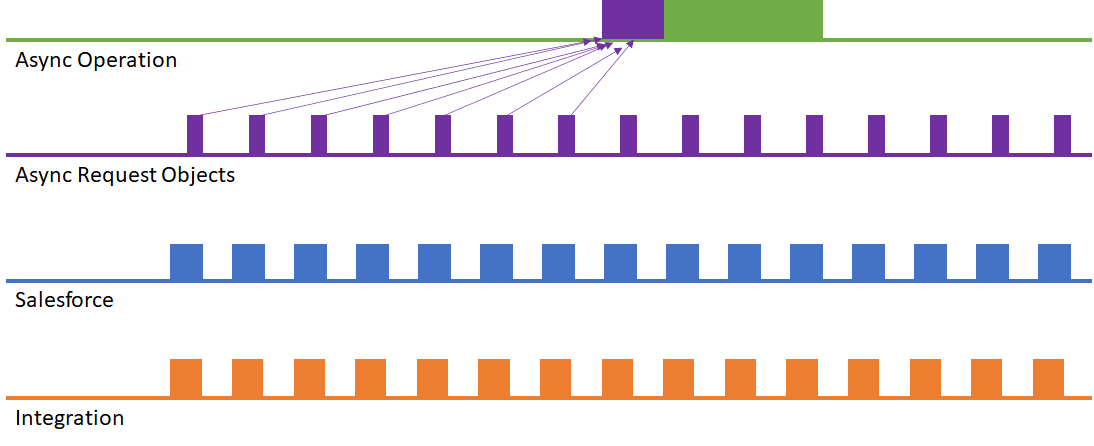
This approach has many advantages
- No possibility of data loss – failing operations are marked on the async request object where they can be tracked or retried.
- Always runs in asynchronous context limits
- You can support different types of async operations with a single custom object
One final comment. This approach is not theoretical. It’s the one we use at Full Circle Insights in our own applications, and we’ve been gradually adding logic to merge different types of async requests as we’ve seen more of our customers run into ill-behaved integrations.



