I know what you’re thinking. What is “dynamic bulkification”? Is it some new terms that I’ve just made up to represent some wild new Apex design pattern?
Yep, that’s about right.
I discuss this in my April appearance in Salesforce Apex hours – you can watch the full video here:
Or, you can read about it in this article below.
Let’s Talk About Integrations
As an ISV partner, I see a lot of orgs. Many of them have integrations with outside services that use APIs to insert and update Salesforce records. Historically, integrations have used the SOAP API, though recently more of them are using the REST API.
The SOAP API is not an easy one to use. It uses XML as the data format and is programmatically rather complex. The REST API is much simpler and uses the common JSON format. So it makes sense that new integrations are using REST and older ones gradually migrating to it. However, the SOAP API does have one advantage over REST – all of the Salesforce SOAP API commands use arrays for transferring record information. In other words, bulk operations are just as easy as individual record operations. So integrations using SOAP would typically perform bulk operations.
You can perform bulk operations with the REST API – they are called composite operations, but they are more complex than the default single record operations. The documentation covers them almost as an afterthought. As a result, anyone learning how to use the Salesforce REST API will inevitably learn the single object patterns first, and may never even notice the composite patterns. Indeed, if you don’t read the documentation carefully, you might conclude that the single object patterns represent best practices.
As a result, we’re seeing more and more orgs that are experiencing a very high frequency of single record operations from integrations. This is not a good thing.
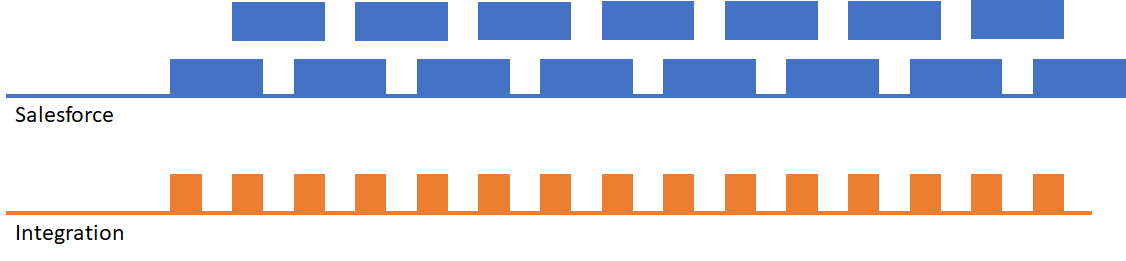
High Frequency Record Operations
Consider a relatively simple org – one with few triggers and little automation, that is experiencing a high frequency of single record operations. Each incoming API call results in an operation in Salesforce, but as long as the Salesforce processing time is short, you’re unlikely to see any problems.
It’s also unlikely that the company building the integration will see any problems, because this is very likely to be the scenario they test for.
But what happens when you start adding additional functionality to the record processing in the form of Apex triggers and automation? The processing time for each request will inevitably increase resulting in the following scenario:
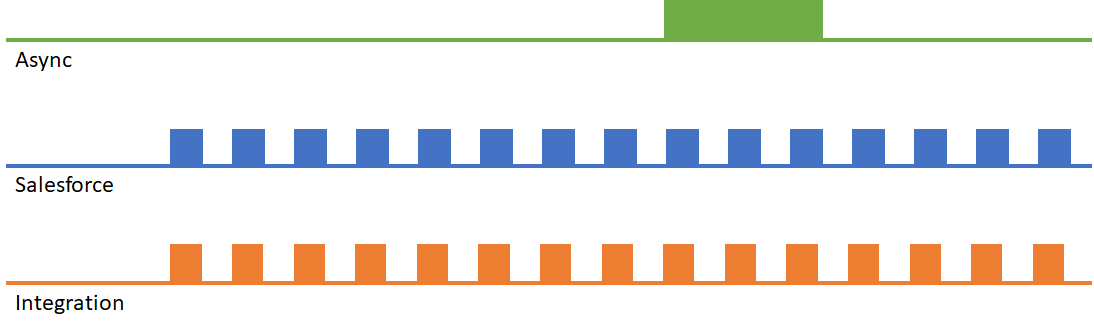
As you can see, Salesforce will still be processing one request when another comes in. However, this may not be a problem, as the different triggers will run in different threads – in parallel. So everything is fine unless…
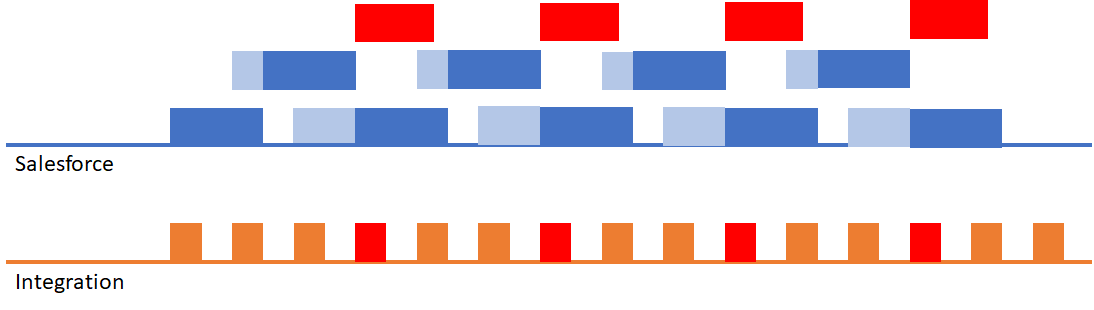
High Frequency Record Operations with Locking
What happens if the API request and corresponding Apex and automation causes a record lock? This can happen when trying to insert or update records that reference a common object. For example: if you tried to update multiple contacts on the same account. The one we see most often is that of a marketing or sales automation system that is trying to insert multiple CampaignMember records on the same campaign – each individual insertion creates a lock on that campaign.
This results in the following scenario (where a red block indicates a locking error):
In this scenario you’ll starting seeing API failures on the integration due to record lock errors.
How can you address this scenario?
You could ask the integration vendor to stop performing individual record operations and bulkify their integration. That’s the right solution, but good luck convincing them to do so. No, in the real world it’s up to you to resolve this.
The obvious first solution would be to reduce the processing time for those individual record operations. You’re probably already familiar with the best ways to do this:
Dump Process Builder (Use flows or Apex – process builder is horrifically inefficient)
Prevent reentrancy (triggers that invoke automation that invoke triggers and so on)
Another common approach is to move part of the processing into an asynchronous context, typically a Queueable operation.
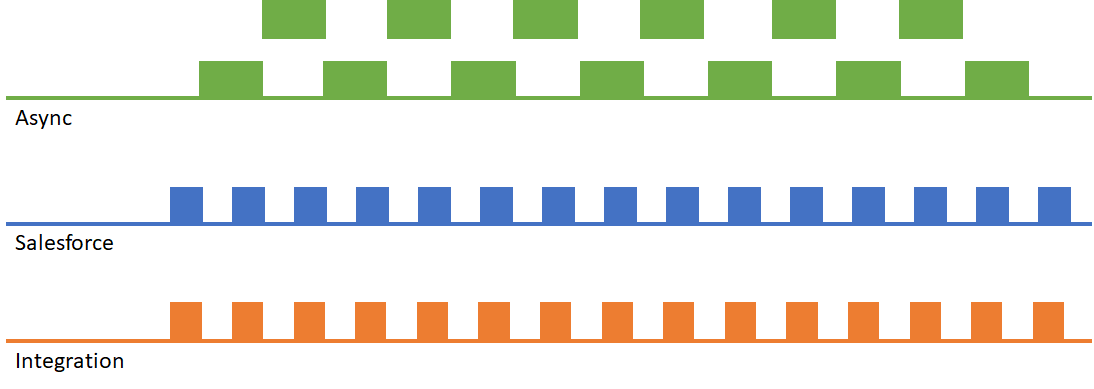
High Frequency Record Operations with Asynchronous Processing
Moving part of your processing into an asynchronous context results in the following scenario:
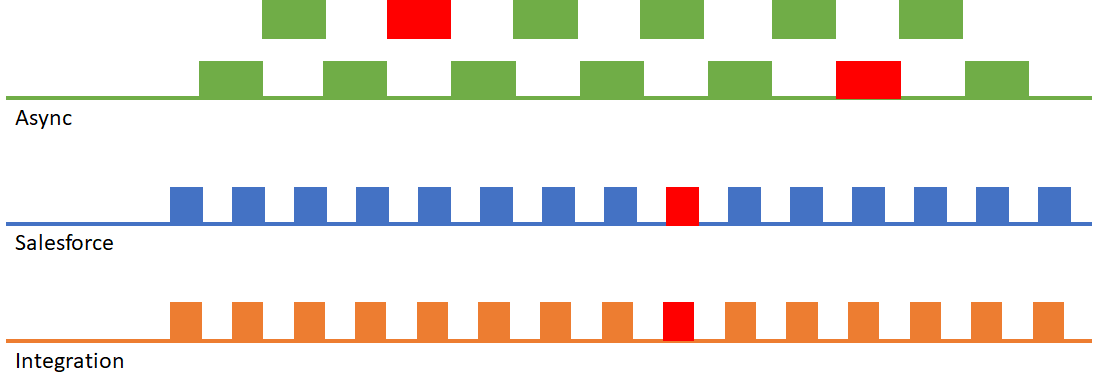
At first glance this looks great. However, it only works if the asynchronous operations themselves don’t perform any tasks that lock records. If they do, you’re liable to end up with the following scenario, where record locking occurs sporadically both on the synchronous operations (resulting in an error being passed back to the integration app), and on the asynchronous operations.
This approach also results in a very high number of asynchronous operations, which can be a problem on larger orgs that are already nearing their 24-hour asynchronous operation limit.
Dynamic Bulkification to the Rescue!
Which brings us to the design pattern that led me to introduce the term “dynamic bulkification”. The idea here is simple – translate large numbers of individual record operations into a single bulk operation as shown here:
I call it “dynamic” bulkification because the individual record operations are combined dynamically at runtime. This approach is a fantastic solution to the problem. That’s because Salesforce is optimized for bulk operations – in most cases the time to perform a bulk operation is far less than the sum of the times of the individual operations. This also results in considerably fewer asynchronous requests, depending on how many single requests can be combined into one.
The question then becomes – how does one implement this?
One approach is to use platform events.
Platform events are self-bulkifying. That is to say, while you may publish individual events, your platform event triggers will always receive groups of events.
While this may seem the ideal solution, there are some problems with this approach:
Platform events are not 100% reliable. Event publishing can fail, and even events that are successfully queued may fail to publish or be delivered.
If your asynchronous operation is inefficient (unbulkified, or performs DML operations that invoke process builder), you won’t gain the full benefits of the bulkification.
Platform events currently run with synchronous context limits (which are lower than the asynchronous context limits).
Platform events are not ISV friendly – there are challenges with incorporating them into packages (platform event limits and quotas are common to the org and packages).
I won’t say that you shouldn’t use platform events for dynamic bulkification. They are probably good enough for most scenarios. But if reliability is a priority, or you are building for an ISV package, they are probably not the right approach at this time.
Dynamic Bulkification with an Asynchronous Framework
A more reliable approach is to build on an asynchronous processing framework. Such a framework uses a custom object – call it an async request object – to represent async requests to be processed. I won’t go into detail on how these frameworks operate, or all of the advantages of taking this approach. You can read all about it in chapter 7 of my book “Advanced Apex Programming”, where I discuss this approach in depth.
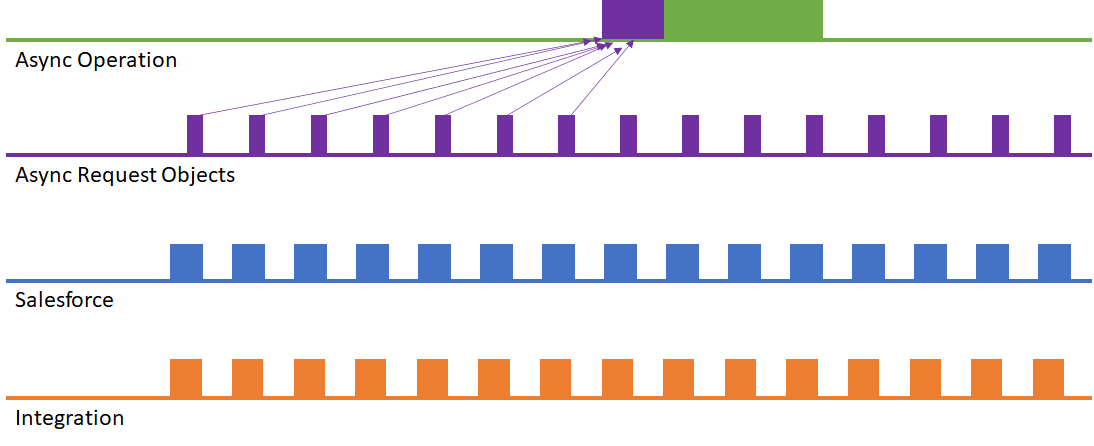
What I don’t discuss in the book is the possibility of merging async request records of the same type in order to perform dynamic bulkification. This results in the scenario shown here:
When an asynchronous operation is about to begin, it performs a query to see if there are any more async requests of the same type that it can merge in order to perform a bulk operation.
This approach has many advantages
No possibility of data loss – failing operations are marked on the async request object where they can be tracked or retried.
Always runs in asynchronous context limits
You can support different types of async operations with a single custom object
One final comment. This approach is not theoretical. It’s the one we use at Full Circle Insights in our own applications, and we’ve been gradually adding logic to merge different types of async requests as we’ve seen more of our customers run into ill-behaved integrations.
I’m pleased to announce the immediate availability of the fifth edition of Advanced Apex Programming!
I know what you’re thinking – what has changed? Do I really need a new edition?
Well, the first thing you should know, is that this book is over 60 pages longer than the previous edition – but that alone does not convey the scope of the changes.
Here’s a brief summary of the major changes for this edition:
Chapter 3: New coverage of the Salesforce platform cache and query selectivity limits.
Chapter 4: Extended to include additional bulk design patterns in the context of enforcing data integrity and addressing data skew.
Chapter 6: This chapter has been completely rewritten with all new examples to incorporate new technologies and modern approaches for refactoring application functionality into decoupled applications or packages.
Chapter 7: The chapter and examples have been rewritten to address batch apex exception events and queueable transaction finalizers. Other new topics include the challenge of dealing with transactions in the context of callouts, suicide scheduling and change data capture.
Chapter 9: The section on working with custom metadata has been completely rewritten to reflect improvements in the technology. The Aura sample code has been reimplemented as Lightning web components.
Chapter 10: The chapter and examples have been updated to be based on the new trigger examples in chapter 6.
Chapter 12: Revised recommendations for unit tests and managed packages.
So even if you don’t buy this new edition, please don’t read the previous one – the platform has changed, and many of the earlier recommendations no longer reflect best practices. Especially when it comes to trigger design patterns!
By the way – the Kindle edition is still priced considerably lower than the print edition – so that offers an inexpensive way to check out what’s new without buying a new printed book, for those of you who are more cost sensitive (I do recommend the printed book in general though, as listings just don’t come through that well in the eBook editions).
As always, watch for corrections and updates here on advancedapex.com – as I’m quite sure Salesforce will continue to update the platform faster than I can revise the book 🙂
I’m pleased to announce the publication of my Pluralsight course “Salesforce and Apex Fundamentals for Developers” – the third update to my original Force.com and Apex Fundamentals for Developers course.
I know what you’re thinking – what has changed (aside from the obvious name change due to the diminishing use of Force.com)?
Most of changes relate to the part of the course that discusses development processes and methodologies. Which is a fancy way of saying: goodbye Force.com IDE – Hello SFDX.
Aside from SFDX, there is some new content – basically covering Apex and platform changes over the past couple of years.
This course is intended to guide software developers who have experience on other platforms to quickly transition to Salesforce Apex development. New developers should consider my other recent course “Salesforce Development: Getting Started“
I recently published a new course on Pluralsight: “Salesforce Development: Getting Started” which is designed to be one’s very first introduction to Salesforce for developers and admins. It starts out in a way that most would find familiar: how to sign up for a developer org, an introduction to orgs and metadata – you know, the way everyone learns Salesforce.
But then I do something different. I talk about metadata, the source of truth, and Salesforce DX (SFDX). In fact, most of the course is about SFDX and how to use it. Not only that, but I’m very intentional about not focusing entirely on code. Automation and other metadata is given more or less equal time and emphasis. In fact, the alternate title for this course is “An Admin’s Guide to SFDX”.
You see, SFDX may draw on techniques familiar to software developers, but SFDX is not about managing software or code. SFDX is about managing metadata. All types of metadata.
SFDX is not about managing software or code – SFDX is about managing metadata
I truly believe it should be the among the first things every future Salesforce developer and admin learns – maybe the very first thing.
I had great fun writing my recent article “Objects, Relationships, and the Cat” in which I shared one of the things I enjoyed most about working on the Salesforce platform using a rather unconventional story-telling style. In fact, I enjoyed it so much, and based on the positive feedback from readers, I thought I’d do it again. As before, this is a work of fiction with the exception of the technical aspects.
I didn’t really notice that the conversation between my housemate and Angie had gotten louder. I was accustomed to their heated technical discussions. After all, spending several months mostly stuck indoors during a pandemic hadn’t exactly put us in a state of mind to be calm or quiet. Still, I probably wouldn’t have noticed them at all had they not suddenly become very quiet.
Their silence was probably a result of my earth-shattering sneeze. I pulled off my headphones, rubbed my nose, and stared at the cat gazing at me from the bookshelf beside my desk. She didn’t look the slightest bit guilty.
“You didn’t take your allergy medicine this morning, did you?” my housemate asked. I nodded. The pills are the price I pay for us having adopted a cat. I grabbed one and washed it down with some warm lemonade.
“Okay,” I sniffled, knowing that I wouldn’t be able to concentrate for a while. “What are you two arguing about now?”
“My customer has a tough set of requirements with an impossible deadline and budget,” answered my housemate. “And we can’t agree on the best way to approach it. You’ve done enterprise software – care to give it a look?”
“Sure,” I replied. “It can’t be harder than living with the cat.”
“It’s a corporate application,” he started, ignoring my comment. “Nothing special in terms of the database schema – a few related tables with some columns and a straightforward UI—just a few fields. Authentication is easy enough. They use single sign-on through a third party OAuth provider and their corporate users already have accounts. The kind of thing that any web framework can support easily.”
“That doesn’t seem too bad,” I said. “So, what’s the issue? And why did you call in Angie?”
People who know of my work in the Windows world sometimes ask me how I, a “real” programmer and former Microsoft MVP, could become so involved with Salesforce development. I thought I’d write a different kind of article highlighting one of the Salesforce platform features that I find compelling—and that makes Salesforce, for me, a serious platform for software development. Instead of the usual “dry” technical article, I present to you a story – a work of fiction (except for the technology, which is all true).
My housemate’s voice just barely infringed on my attention. “They deleted a field!” he yelled.
It wasn’t enough to distract me from my latest binge-watching effort.
“THEY DELETED A FIELD!”
The second time I couldn’t ignore him. I turned around to find quite a sight. He was on his feet shouting at the screen. Worse yet, he disturbed the cat, who decided I was the safest refuge. I reached for another allergy pill. Why we got a cat given my allergies, I have no idea.
“What’s going on?” I asked, trying to sound supportive. We’d both been working from home, sheltering in place for several months now, and I counted myself lucky—we still got along. Still, better him shouting at some remote miscreant than at me. “Who deleted what?”
He took a deep breath and explained. “Part of my client’s application went down yesterday, and they’ve been yelling at me to fix it,” he started. “It uses an Object Relationship Mapping library to make it easy to code against the database, and I was thinking it might have changed during a recent update. But it turns out that one of the client’s DBAs decided that a particular database column was no longer needed, and removed it.” He shook his head. “I just can’t believe it.”
Okay, I’m a nice guy, but I couldn’t resist.“I can’t believe it either – it has to be something else. You can’t delete a column that’s in use.”
“Of course you can’t, that’s why it failed,” he explained.
“No, you can’t,” I said. “It’s not possible. If the column is in use, the database won’t let you delete it.”
Now he looked at me like I was crazy. Well, crazier–both of us were now three months without a haircut, so looking crazy was becoming the new normal.
“What do you mean the database won’t let you delete it?” he asked. “The database doesn’t care what you delete. It’s a database.”
I decided to be stubborn for just a bit longer. “You yourself said you were using an ORM library–so yes, the database should know the column is being used. After all, you’ve defined the objects and fields that map to the tables and columns–so the information is available. Right?”